The Challenge
At the turn of the AI explosion, many hardware companies were trying innovative approaches to solving LLM workloads. Here at JDBC, we adopted a novel approach to solving LLM workloads using Approximate Matrix Multiplication (AMM). These type of operations are not conducive to GPU-based approaches since the random access nature of the operation causes most caches to be invalidated. We knew that new hardware would be needed to solve this problem and we started with an FPGA-based approach to validate the concept.
The ONNX Runtime by Microsoft is a open-source library for running machine learning models on a variety of hardware platforms. We identified it as a good fit for our approach and we started by building a custom execution provider for the ONNX Runtime.
Our Approach
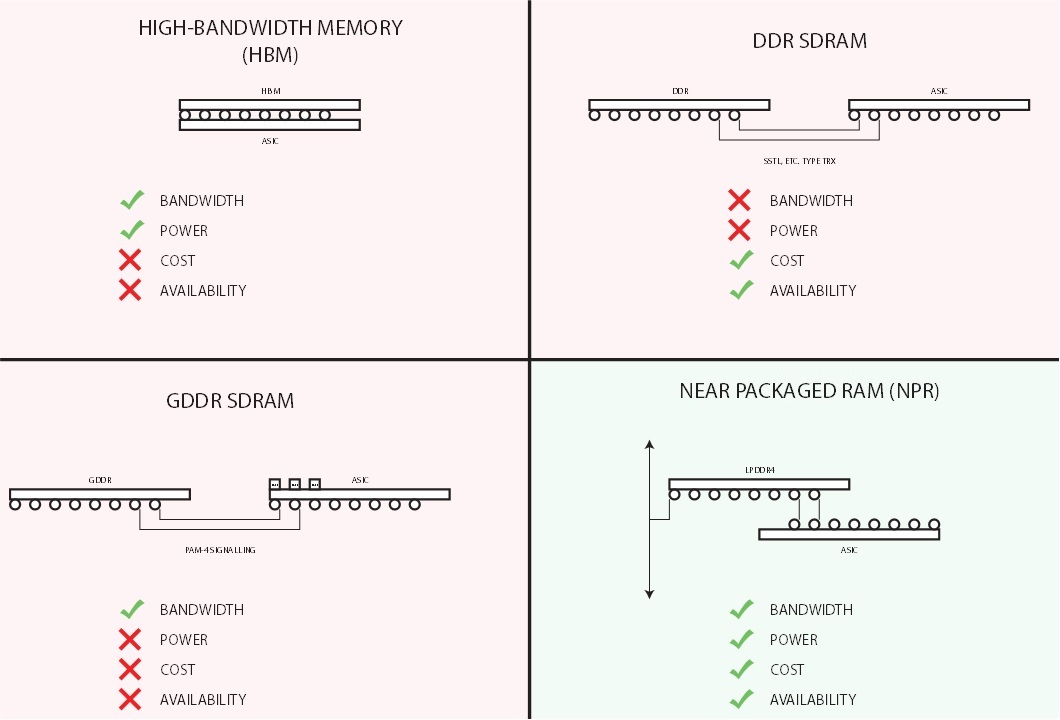
The Memory Bottleneck
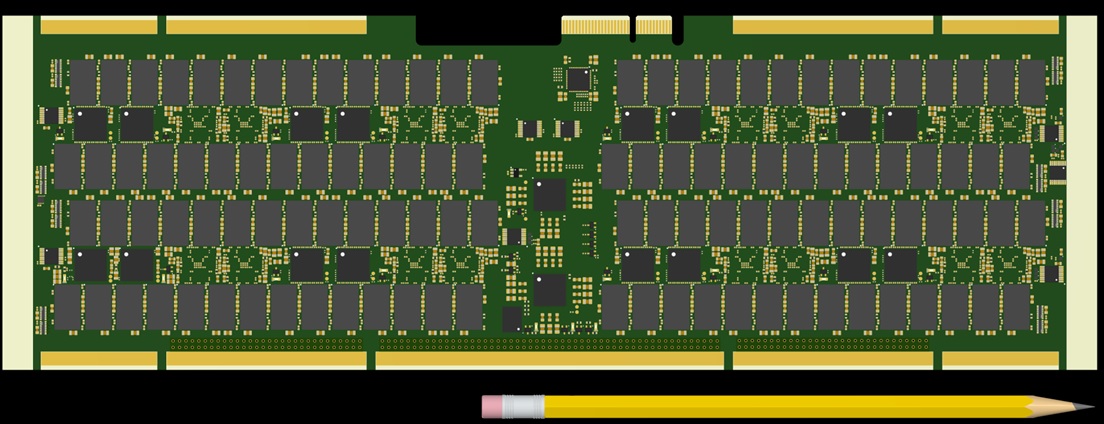
Besides being in short supply, non-HBM high-performance DRAM has very high power-consumption. Settling on DDR3, we identified a novel memory bus architecture which reduced power consumption and improved throughput by using a fly-by topology with over 100 drops. Signal integrity was achieved with exquisitly detailed simulations, layout, and fabrication binning.
Further, power consumption was reduced on the data bus with electrically short routing and weak termination. Power consumption rivaled that of HBM. To reduce costs, Efinix Titanium FPGAs were used.
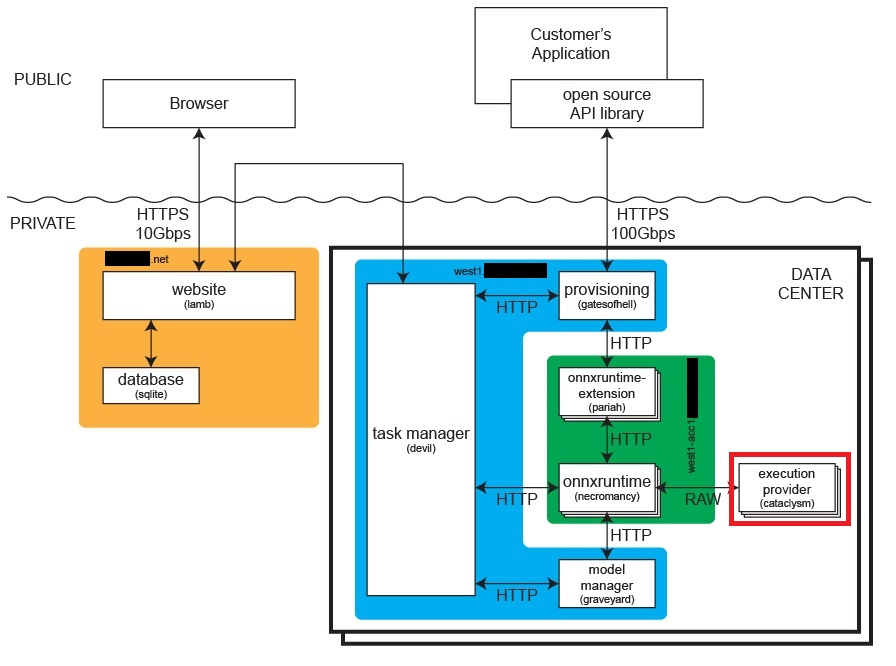
Custom Execution Provider Architecture
We developed a custom ONNX Runtime execution provider over ethernet that could execute arbitrary ONNX models, including the latest LLM models such as Llama. While moving data to the accelerator card was slow, it only had to be done when the weights were changed. This architecture enabled ultra low-cost hardware.
Results
While the PCB was completed, simulation showed the Approximate Matrix Multiplication (AMM) algorithm was too noisy for LLM workloads, and the HPC landscape became even more competitive, so we opted to cancel the project. However, many lessons were learned.